一种分布式的计算方式指定一个Map(映#x5C04;)函数,用来把一组键值对映射成一组新的键值对,指定并发的Reduce(归约)函数,用来保证所有映射的键值对中的每一个共享相同的键组
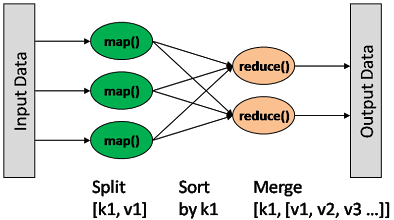
map: (K1, V1) → list(K2, V2) combine: (K2, list(V2)) → list(K2, V2) reduce: (K2, list(V2)) → list(K3, V3)
Map输出格式和Reduce输入格式一定是相同的
MapReduce主要是先读取文件数据,然后进行Map处理,接着Reduce处理,最后把处理结果写到文件中
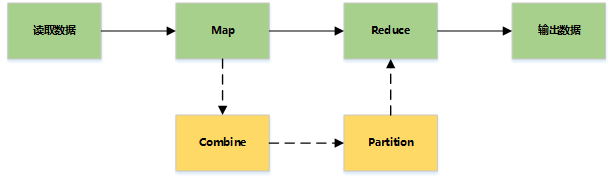
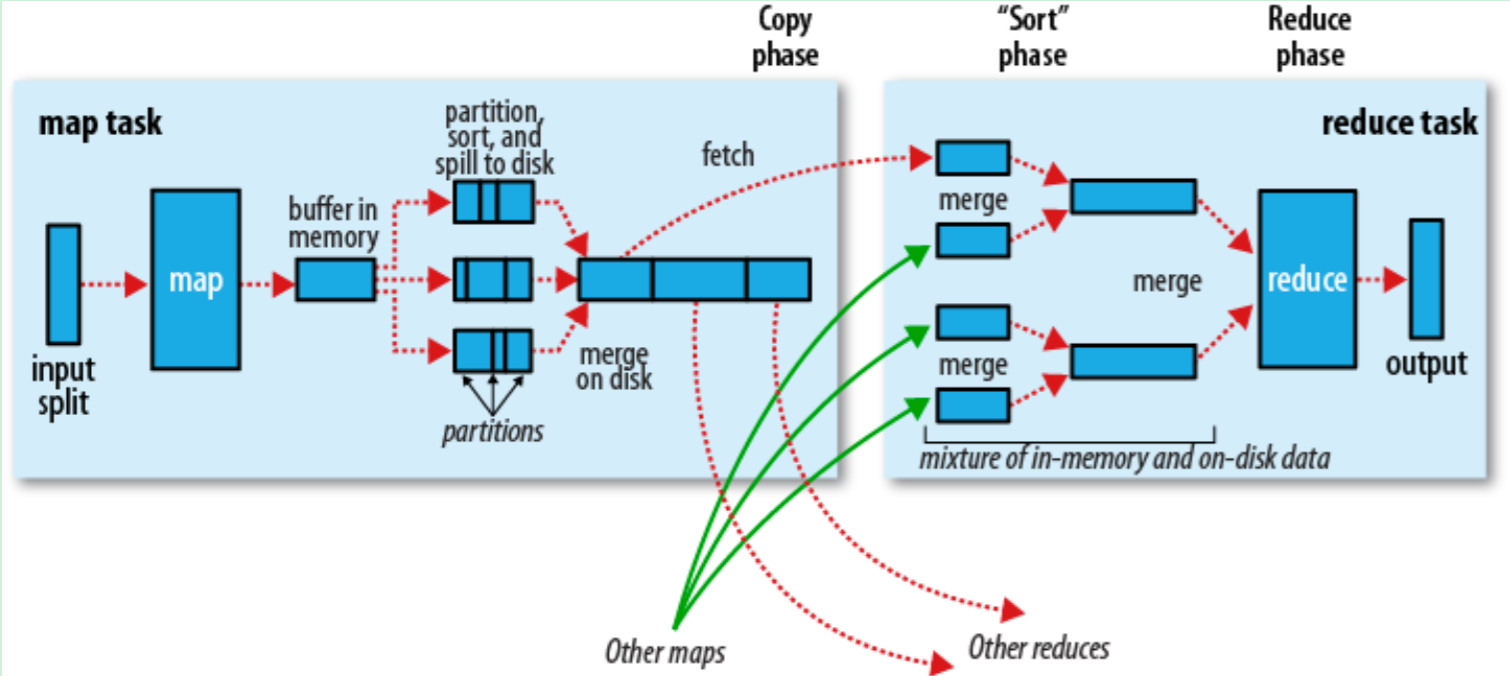
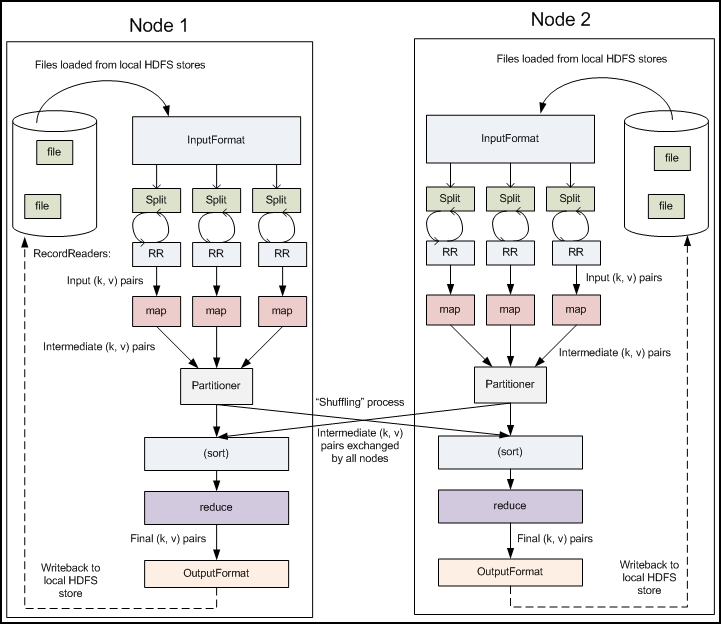

记录阅读器会翻译由输入格式生成的记录,记录阅读器用于将数据解析给记录,并不分析记录自身。记录读取器的目的是将数据解析成记录,但不分析记录本身。它将数据以键值对的形式传输给mapper。通常键是位置信息,值是构成记录的数据存储块.自定义记录不在本文讨论范围之内.
在映射器中用户提供的代码称为中间对。对于键值的具体定义是慎重的,因为定义对于分布式任务的完成具有重要意义.键决定了数据分类的依据,而值决定了处理器中的分析信息.本书的设计模式将会展示大量细节来解释特定键值如何选择.
ruduce任务以随机和排序步骤开始。此步骤写入输出文件并下载到本地计算机。这些数据采用键进行排序以把等价密钥组合到一起。
reduce采用分组数据作为输入。该功能传递键和此键相关值的迭代器。可以采用多种方式来汇总、过滤或者合并数据。当reduce功能完成,就会发送0个或多个键值对。
输出格式会转换最终的键值对并写入文件。默认情况下键和值以tab分割,各记录以换行符分割。因此可以自定义更多输出格式,最终数据会写入HDFS。类似记录读取,自定义输出格式不在本书范围。